
一、问题背景
如今,网络数据量正在以一种超线性的方式增长,Web 应用不再仅仅服务于传统的单一、小文件上传下载,而是需要处理大规模数据的上传,例如机器学习和人工智能行业中的数据训练、模型训练等,文件大小可能会达到数十GB甚至上百GB。
But,用户在上传大量文件数据时,可能由于网络波动导致上传过程在很长时间之后失败,所有的上传进度和时间都会白白浪费,这对用户体验来说是极其不友好的。此外,浏览器中的 JavaScript 单线程运行,处理大文件上传的同时可能会引发其他任务的阻塞问题,导致浏览器假死或者崩溃。同时,由于服务端一次需要接收大量的数据,对服务器带宽和存储也是一种非常大的压力,极大可能导致服务端过载。
为了能够解决上述问题,通常而言我们建议设计并实现一个较通用、稳健的文件分片上传功能。通过将一个完整的文件分片成多个小份,这样每一份较之一个完整的大文件都小很多,上传的速度会得到相应的提升,同时尽可能降低了因为网络波动导致的上传失败的风险。在一次小份文件上传完成后,即使在后续的上传过程中出现了网络波动,用户也只需要从出错的那一个分片开始重新上传,大大节省了用户的等待时间。
总的来说,实现分片上传机制是为了在提升系统健壮性的同时优化用户体验,尤其是在处理大文件时候,其优势更为明显。
二、基本方案
将单个大任务拆解成多个小任务,一方面能够有效避免单个大任务超时情况;另一方面子任务出错时,只需要重试该子任务即可;
服务端需要知道什么时候算是接收完了:有哪些子任务,以及切片的索引;
服务端接收到所有数据后,需要按照切片索引顺序合并恢复,并存储到云存储环境中(oss);
三、具体方案
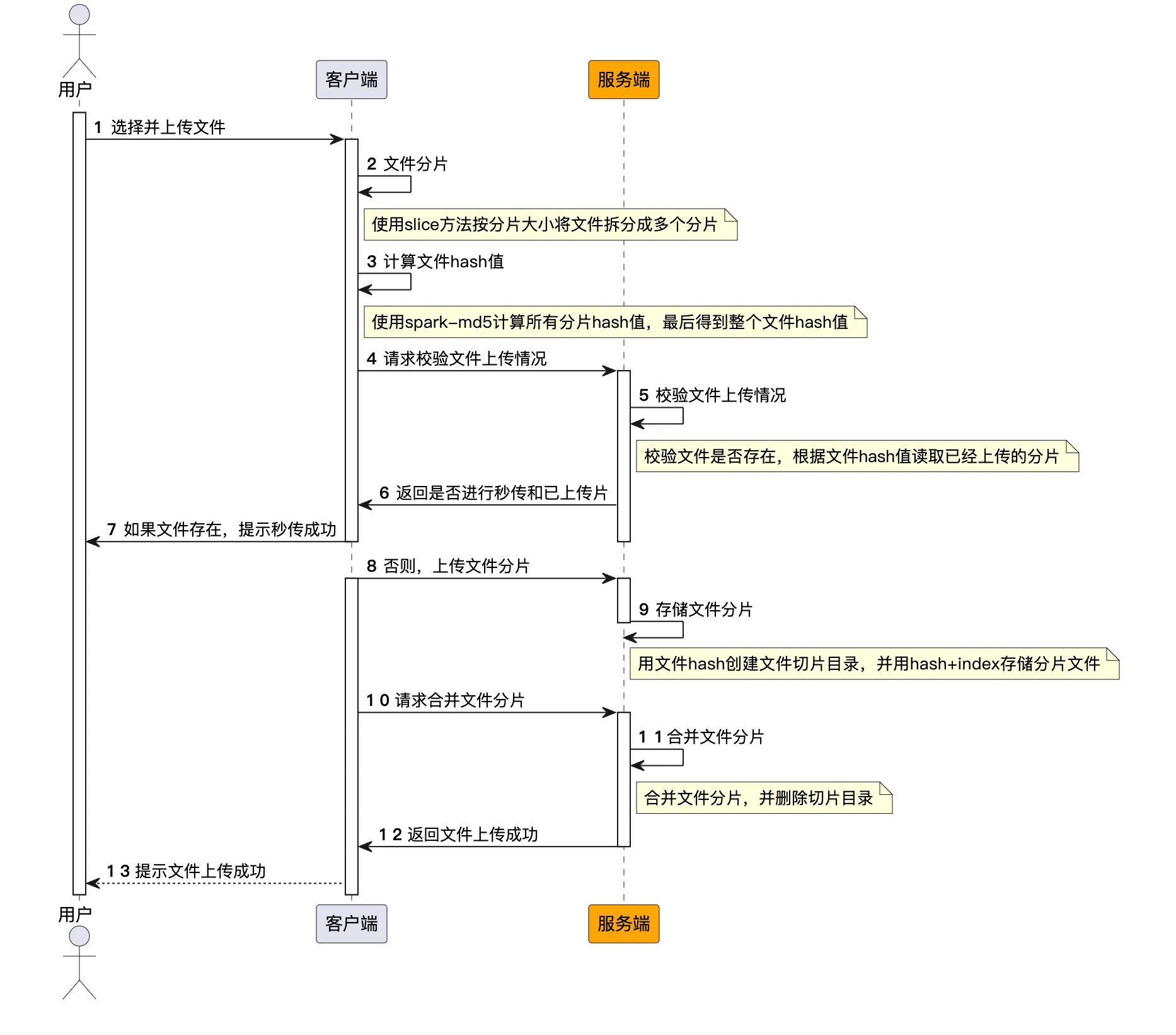
选择文件:当用户通过浏览器选择一个文件进行上传时,第一步是获取该文件的 MD5 值,该值将用作后续操作的唯一文件标识。这一阶段主要完成两项工作:
A. 计算文件 MD5:浏览器计算文件内容的 MD5 值,作为该文件的唯一标识。
B. 服务器确认:该 MD5 值被发送到服务器以确认该文件是否已存在。如果服务器已有该文件,该操作将直接停止,实现文件秒传功能。
文件切割与索引:为了优化上传流程,需要把大文件分割成多个小切片,并为每个切片创建一个索引。这一阶段主要完成三项工作:
A. 文件切割: 使用 file.prototype.slice 方法将文件切割成多个小块;
B. 索引记录:记录每个文件切片的索引,并为其计算 MD5 值。这将作为后续操作的重要参考数据;
C. 本地保存(可选):将文件切片及其相关信息(索引、MD5值)存储到浏览器的 IndexedDB 中,以实现在页面刷新后能够重新开始上传。
服务端创建上传任务:在浏览器完成文件切割和索引记录后,会将这些信息发送到服务器以创建一个上传任务。服务器在接收到这些信息后会记录和创建相应的任务。
分片上传与秒传:在确保文件切片信息准确无误后,浏览器会开始逐个上传这些文件切片。在上传每个文件切片之前,会先发送切片的 MD5 给服务器,用于判断该切片是否已存在于服务器中。如果服务器已经有了这个切片,就直接跳过这个切片,进入下一个,从而实现切片级别的秒传。
浏览器端用户体验优化:为了提供更好的用户体验,我们可以实时展示文件上传进度,并允许用户在必要时取消上传。这种取消上传的机制应允许用户在稍后的任何时间内继续上传,而不会丢失任何已上传的进度。
调用服务端接口,执行合并还原操作;
进阶功能:
有没有可能使用 websocket、webworker 进一步提速?
上传之前可否使用 jszip 压缩内容(压缩率)?
如何实现暂停、取消?
四、源码实现
源码A,使用axios为前后端交互基础
源码B,使用websocket为前后端交互基础,使用jszip压缩内容
都实现了webworker切片,暂停、取消等基础操作
如何运行?
npm i -g pnpm @microsoft/rush // 安装pnpm 与 rush
rush update // 安装依赖
// 运行大文件上传服务端
cd apps/upload-file
npm run dev
// 运行大文件上传客户端
cd apps/upload-file-vue
npm run dev更细节的rush操作方法参考这篇文章 -> Monorepo-rush的入门操作
为啥不贴代码?
因为代码量很多影响观看,大家看到实现原理后就可以知道实现流程。如果对流程有疑问,再去花时间看源码就好了。


